IA : Au-Delà de la Science-Fiction, une Révolution Réelle
Aujourd’hui, je prends la plume en tant qu’auteur invité désireux de toucher le plus grand nombre. Avec cette introduction, je souhaite partager la passion qui me pousse à initier les passionnés à l’intelligence artificielle. Ces écrits sont le reflet d’un travail de longue haleine, une invitation à plonger dans le monde fascinant de l’IA, débutant par une remise à niveau essentielle.

J’espère que vous apprécierez ce voyage à travers les méandres de l’intelligence artificielle autant que j’ai pris plaisir à le concevoir. Vos retours, critiques ou éloges, seront les bienvenus en commentaire. C’est avec impatience que j’attends de lire vos impressions et, qui sait, d’inspirer chez vous une passion semblable à celle qui m’anime pour ce domaine en constante évolution.
Le Fil Rouge de Notre Voyage dans l’Intelligence Artificielle
Cet écrit, au-delà d’être une compilation de connaissances et d’insights sur la science des datas, aspire à être votre guide de découverte dans un domaine aussi vaste que passionnant: il est temps de dévoiler le chemin que nous allons emprunter ensemble.
Le But de Ce Voyage
L’objectif est double. D’une part, démystifier l’intelligence artificielle, en séparant la science de la science-fiction et d’autre part, rendre accessible à tous les nuances et les complexités de ce champ d’étude. Quelle que soit votre familiarité préalable avec l’IA, ce récit est conçu pour vous fournir les outils nécessaires pour comprendre et apprécier les progrès et les défis de l’intelligence artificielle.
Le Chemin à Suivre
Nous commencerons par poser les fondations, avec un préambule dont l’objectif sera de clarifier les concepts clés et établir une distinction entre la Business Intelligence, le Machine Learning et l’Intelligence Artificielle. Cette étape est cruciale pour appréhender le reste du contenu avec la bonne perspective.
Ensuite, à travers des paragraphes structurés et progressifs, nous explorerons les différentes facettes de l’IA : de ses applications pratiques à ses implications éthiques, en passant par les avancées technologiques qui la rendent possible. Chaque paragraphe est conçu pour construire sur le précédent, permettant ainsi une compréhension graduelle et approfondie du sujet.
L’Approche retenu
Pour rendre ce voyage aussi enrichissant que possible, l’approche adoptée sera à la fois académique et accessible. Des exemples concrets, des études de cas et des anecdotes viendront ponctuer les explications techniques, rendant les informations non seulement digestes mais également captivantes.
Mon souhait est de créer un dialogue avec vous, lecteurs, dans lequel vos questions et curiosités trouveront des réponses claires et des réflexions stimulantes.
Importance de l’IA dans le Monde Moderne
Dans le monde moderne, l’intelligence artificielle est devenue un pilier central dans de nombreux secteurs, révolutionnant la manière dont nous vivons, travaillons et interagissons. De l’optimisation des chaînes d’approvisionnement à la personnalisation des expériences utilisateur en ligne, de la prédiction des tendances du marché à l’automatisation des tâches domestiques, l’impact de l’IA est omniprésent. Son rôle est également crucial dans la résolution de certains des défis les plus pressants de notre époque, tels que le changement climatique, la santé globale et la sécurité alimentaire, en fournissant des outils pour analyser de grandes quantités de données et générer des solutions innovantes.
L’importance de l’IA dans le monde moderne ne réside pas seulement dans son potentiel à améliorer l’efficacité et à ouvrir de nouvelles voies d’innovation, mais aussi dans sa capacité à transformer fondamentalement les structures économiques, sociales et culturelles. Alors que nous nous orientons vers un avenir de plus en plus intégré à l’IA, il devient impératif de réfléchir de manière critique aux implications éthiques, à la gouvernance et à l’équité de ces technologies.
Brève Histoire de l’IA et son Évolution
Dans le sillage tumultueux de l’histoire humaine, l’intelligence artificielle s’est frayé un chemin, passant en quelques décennies de la simple curiosité scientifique à une force motrice de l’innovation moderne.
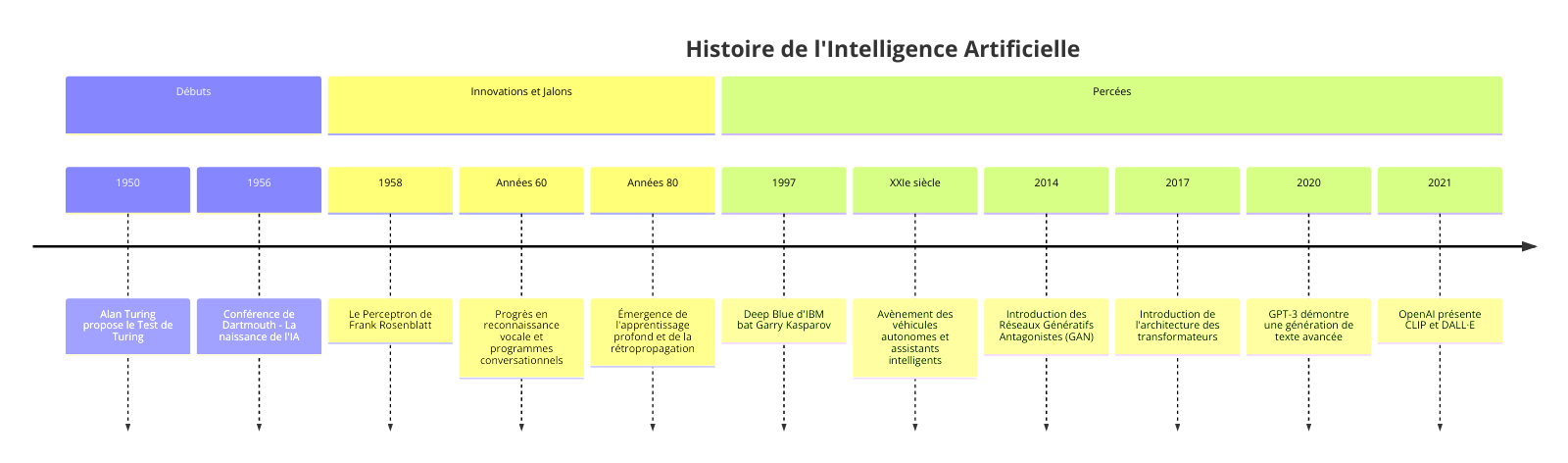
L’histoire de l’intelligence artificielle est jalonnée de développements théoriques, d’avancées technologiques et de débats philosophiques. Les racines de l’IA remontent aux années 1940 et 1950. Depuis, l’IA a connu plusieurs « hivers », périodes marquées par un scepticisme et un financement réduit, alternant avec des « étés » de progrès et d’optimisme renouvelé.
Chaque époque a vu émerger des visionnaires, des penseurs et des bâtisseurs qui, pièce par pièce, ont construit l’édifice que nous admirons aujourd’hui. Au commencement des années 1950, Alan Turing, un pionnier dont la clairvoyance scientifique ne connaissait pas de bornes, posait une question audacieuse : une machine peut-elle penser ? Avec son Test de Turing, il a non seulement donné naissance à un défi qui perdure jusqu’à aujourd’hui, mais a aussi semé les premières graines d’une révolution à venir. Ce test, simple en apparence, demandait si une machine pouvait imiter l’intelligence humaine au point de tromper un interlocuteur.
C’était la première pierre de l’édifice.
L’année 1956 fut témoin d’un moment charnière, les Conférences de Dartmouth (18 juin – 17 août 1956) organisées par Marvin Minsky, où des esprits brillants se sont réunis sous la bannière d’une idée révolutionnaire : l’intelligence artificielle. Cet événement a non seulement baptisé le domaine, mais a également allumé la mèche de la recherche et de l’innovation qui allait suivre. Peu après, en 1958, le Perceptron de Frank Rosenblatt a montré au monde que les machines pouvaient apprendre, adaptant leurs réponses à partir des données fournies.
C’était un premier pas vers la compréhension que les machines pourraient non seulement penser, mais aussi évoluer.
Les années 60 ont été marquées par des avancées telles que Shoebox d’IBM, capable de reconnaître la parole, et ELIZA, un programme qui pouvait mener une conversation, bien que rudimentaire. Ces innovations ont ouvert la voie à la reconnaissance vocale et au traitement du langage naturel, montrant que l’interaction entre l’homme et la machine pourrait devenir aussi naturelle que la conversation humaine. Avec l’avènement de la rétropropagation dans les années 80, l’apprentissage profond a pris son envol, permettant aux réseaux de neurones d’atteindre une complexité et une efficacité sans précédent.
Cette période a marqué un tournant, propulsant l’IA de la théorie vers des applications pratiques qui ont commencé à remodeler le monde.
L’année 1997 a vu Deep Blue d’IBM battre le champion du monde d’échecs Garry Kasparov, un exploit qui a démontré au grand jour la capacité des machines à surpasser l’intelligence humaine dans des tâches spécifiques. C’était un signal clair que l’IA n’était plus confinée aux laboratoires de recherche, mais prête à entrer dans la vie quotidienne des gens. Le XXIe siècle a accueilli des innovations comme Stanley, le véhicule autonome de Stanford, et l’avènement des assistants personnels intelligents tels que Siri, ouvrant la porte à une ère où l’IA assiste activement les humains dans leurs déplacements et leurs interactions quotidiennes.
IBM Watson, en remportant « Jeopardy! », a non seulement divertit le public, mais a également illustré la capacité de l’IA à comprendre et à traiter le langage humain à un niveau avancé. L’introduction des réseaux génératifs adverses (GAN) en 2014 et des architectures de transformeurs en 2017 a marqué le début d’une nouvelle ère dans laquelle l’IA n’est plus seulement un outil d’analyse, mais aussi un créateur, capable de générer du contenu visuel et textuel d’une qualité stupéfiante. En 2020 avec l’arrivée de GPT-3, le monde a été ébloui par sa capacité à produire du texte d’une fluidité et d’une cohérence remarquables, ouvrant des perspectives nouvelles pour la création de contenu, l’éducation et au-delà. Puis, en 2021, CLIP et DALL·E d’OpenAI ont révolutionné notre compréhension de l’interaction entre texte et image, illustrant une fois de plus l’incroyable polyvalence de l’IA.
Les avancées récentes en puissance de calcul, en capacité de stockage de données et en algorithmes d’apprentissage profond ont propulsé l’IA au premier plan de la recherche et de l’innovation technologique, ouvrant des possibilités auparavant inimaginables.
Comprendre les Fondamentaux – BI, ML et IA
Dans un monde de plus en plus piloté par les données, la capacité à les comprendre, les analyser et les utiliser pour prendre des décisions éclairées est devenue cruciale pour les entreprises de tous les secteurs. Ce pré-paragraphe se consacre à démêler les concepts de la Business Intelligence (BI), du Machine Learning (ML) et de l’Intelligence Artificielle (IA) – trois piliers de la science des données qui transforment notre façon d’interagir avec le monde numérique.
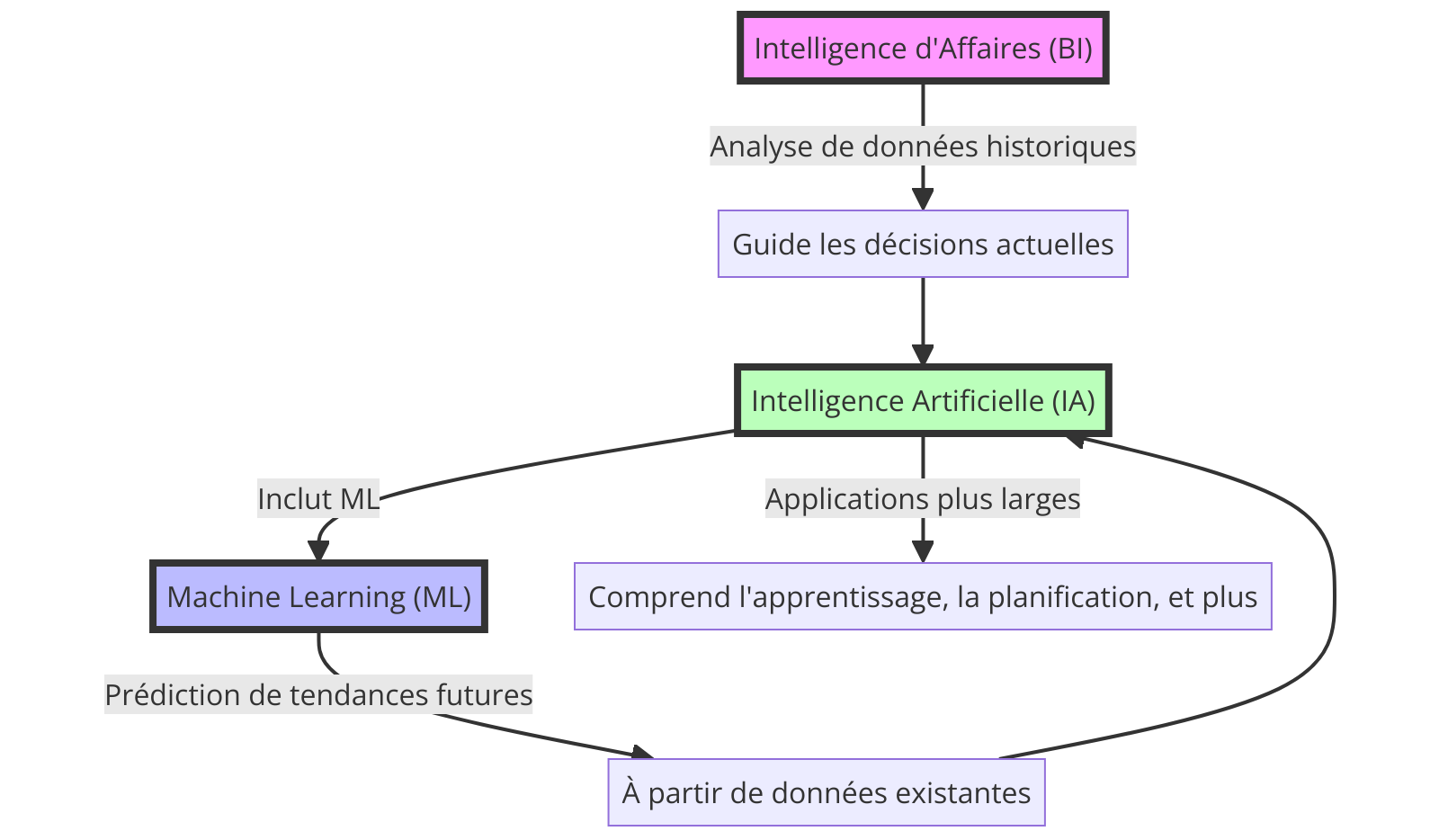
Business Intelligence (BI)
La Business Intelligence englobe les technologies et les stratégies utilisées par les entreprises pour l’analyse de données. Elle permet une visualisation interactive de données historiques et actuelles, facilitant ainsi la prise de décisions stratégiques et opérationnelles. À travers des outils comme les tableaux de bord, les rapports et les analyses, la BI transforme de grandes quantités de données brutes en informations exploitables, offrant une compréhension profonde de la performance d’une entreprise et des tendances du marché.
Pour résumer, La BI utilise des outils logiciels pour transformer les données en informations utiles pour les processus décisionnels des entreprises. Elle se concentre principalement sur l’analyse des données passées et présentes pour guider les décisions d’affaires.
Machine Learning (ML)
Le Machine Learning, une sous-branche de l’IA, se caractérise par la capacité des machines à apprendre à partir de données et à s’améliorer avec l’expérience, sans être explicitement programmées pour chaque tâche. Du filtrage des spams dans vos emails à la recommandation de votre prochain film préféré, le ML alimente une gamme étendue d’applications, poussant les limites de ce qui est possible avec l’analyse manuelle des données.
Pour résumer, le ML permet aux machines d’apprendre à partir de données et d’améliorer leurs performances sur des tâches spécifiques avec peu ou pas d’intervention humaine et faire des prédictions ou des recommandations basées sur cet apprentissage.
Les Méthodes de l’Apprentissage Automatique
L’apprentissage automatique est au cœur de nombreuses applications d’IA. Au centre de cette discipline, il y a le concept de “lit. apprentissage” que nous pouvons classer en trois approches afin que la machine puisse observer et prédire le monde autour d’elle.
Apprentissage supervisé
Les modèles sont entraînés sur un ensemble de données étiquetées (par des humains ou plus au moins automatiquement) pour prédire l’étiquette d’un nouvel ensemble de données jamais observé précédemment.
Apprentissage non supervisé
Les modèles analysent et regroupent des ensembles de données non étiquetées en se basant sur les similitudes et les différences dans l’ensemble des données observables et sans aucune intervention humaine.
Apprentissage par renforcement
Les modèles apprennent à prendre des décisions en exécutant des actions et à mesurer les conséquences dans un environnement spécifique, simulé pour maximiser une notion de récompense cumulative.
Cette notion de récompense est souvent mise à point par un humain, qui intervient manuellement ou a décrété les règles d’évaluation dans un programme automatique.
L’apprentissage par renforcement est une catégorie que je définirais de “chapeau” puisqu’elle englobe des dizaines de stratégies diverses mises au point pour donner des feedbacks d’apprentissage à la machine.
Intelligence Artificielle
L’intelligence artificielle est un domaine de l’informatique qui vise à créer des systèmes capables de réaliser des tâches qui, traditionnellement, nécessitent l’intelligence humaine. Ces tâches incluent l’apprentissage, la planification et la compréhension. L’évolution de l’IA, depuis sa conception jusqu’à son intégration dans notre quotidien, illustre non seulement le progrès technologique, mais aussi notre quête incessante pour créer des outils qui peuvent améliorer et étendre nos capacités cognitives et productives.
Cette branche, pour le dire avec d’autres mots, vise à créer des machines capables de penser, apprendre et agir de manière indépendante, imitant ainsi l’intelligence humaine. Allant au-delà du ML, l’IA inclut la robotique, le traitement du langage naturel et la vision par ordinateur, entre autres. Elle ouvre des portes à des possibilités inédites, comme les voitures autonomes, les assistants personnels intelligents et les systèmes de diagnostic technique ou médical avancés, redéfinissant les limites de l’innovation technologique.
L’intelligence artificielle est un champ d’étude fascinant et en constante évolution, caractérisé par sa vaste diversité et ses nombreuses sous-disciplines.
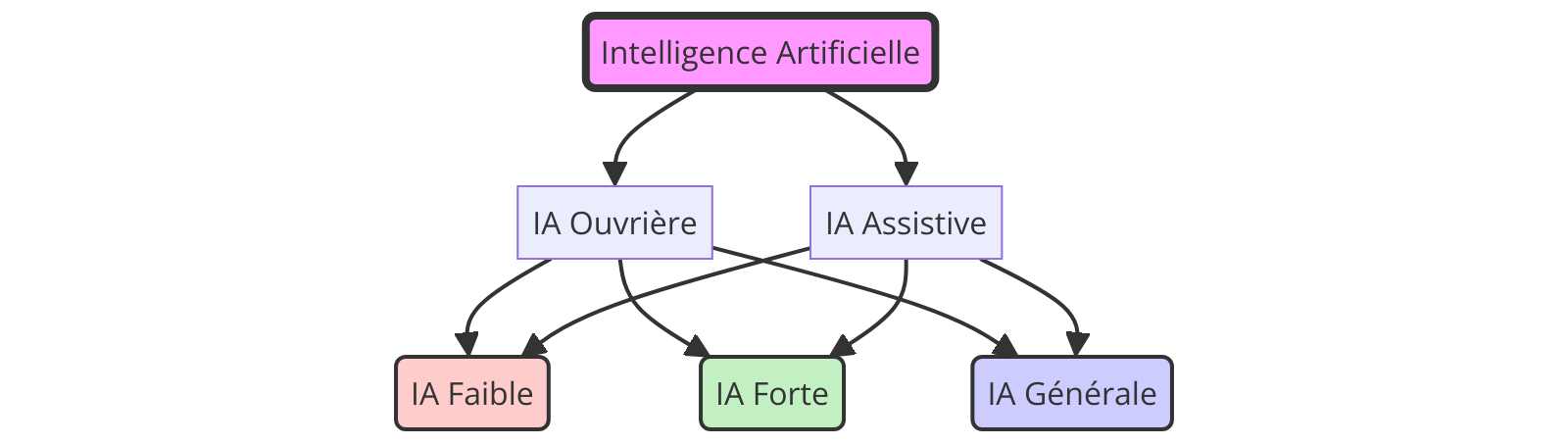
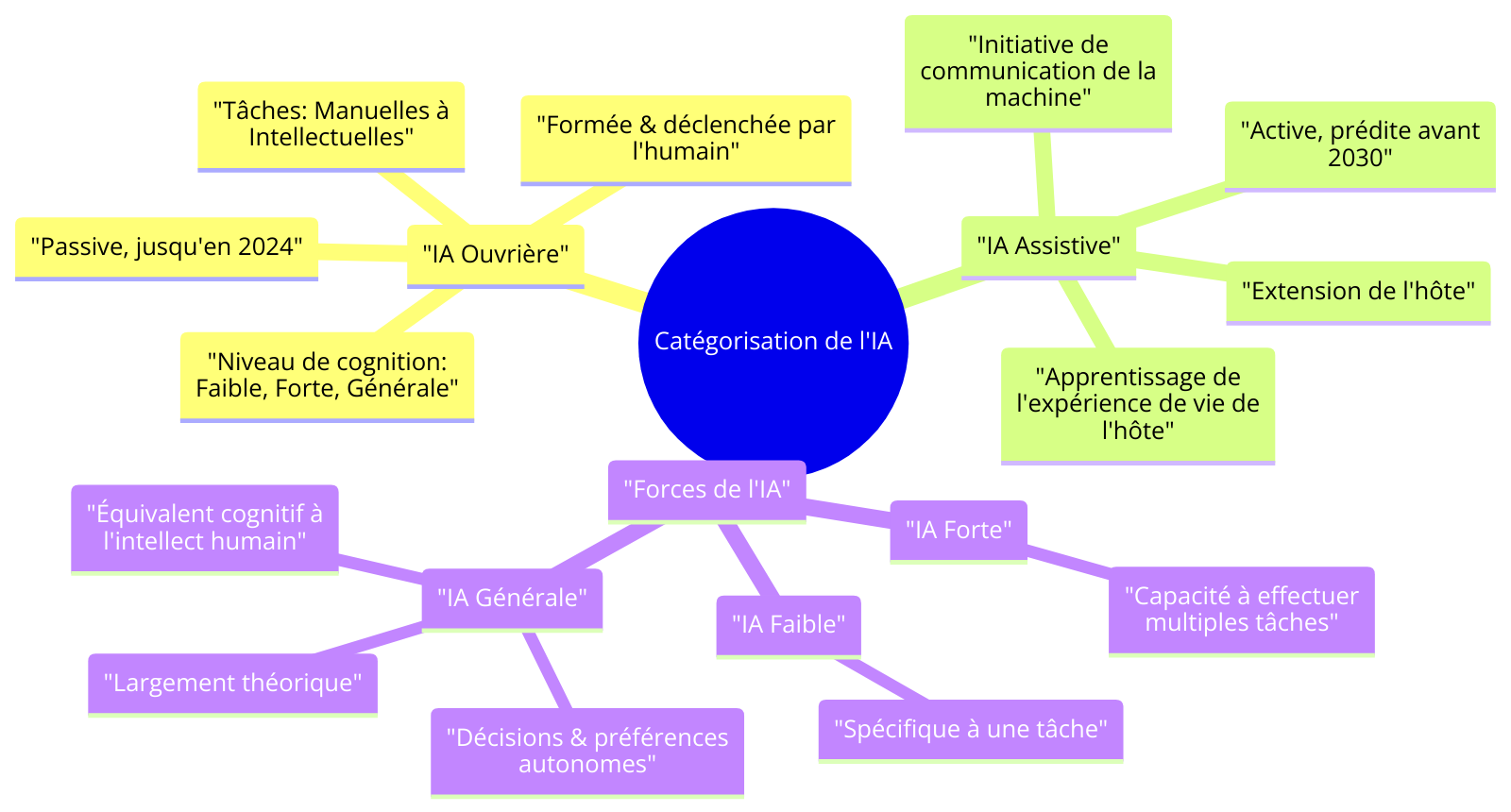
De mes propres recherches et travaux, je partage les IA en Ouvrière et Assistive réparties en 3 catégories: IA faible, forte et générale.
Les IA ouvrières et assistives
Les IA dites “ouvrières” sont les IA passives et correspondent à 100% des IA que nous avons mises au point jusqu’en 2024.
Les IA de cette catégorie oeuvrent pour notre compte sur des tâches plus ou moins manuelles ou même intellectuelles en fonction de leur niveau de cognition qu’il soit faible, fort et même général; plus simplement elles attendent des instructions précises pour opérer. Il s’agit de systèmes qui digèrent des connaissances que nous avons décidé de leur faire ingérer et restituent un comportement qui suit les instructions que nous leur avons donné suite à une stimulation volontaire à notre initiative.
En une phrase, c’est l’humain qui entraîne et déclenche la machine à sa guise de façon descendante.
C’est l’humain qui parle à la machine.
Les IA dites “assistives” sont des IA actives et sont encore de la science-fiction en 2024. Cependant je prédis leur arrivée avant 2030. Les IA de cette catégorie assistent leur hôte et sont donc personnelles par définition, comme une extension de ce dernier. Elles nous permettent de dépasser nos capacités biologiques via une communication descendante de la machine à l’hôte: un exemple, nous reporter dans la limite de notre mémoire à court et moyen terme des informations distillées en fonction du contexte afin de maximiser nos intérêts existentiels; la machine aurait à coeur de nous aider à atteindre nos objectifs. Les IA de cette catégorie vivent à côté de leur hôte et sont entraînées par les expériences de vie de ce dernier, elles apprennent en même temps que ce dernier du monde extérieur et décident par elle-même le champ de leur application.
En une phrase, c’est la machine qui apprend à vivre et se déclenche en fonction d’intérêts communs avec l’hôte. C’est la machine qui parle à l’homme.
Les IA fortes, faibles et générales
Les IA dites “faibles” sont conçues et formées pour une tâche spécifique alors que les IA dites “fortes” possèdent la capacité de comprendre, apprendre et appliquer l’intelligence à une variété de tâches.
Les IA dites “générales” agissent pour leur propre compte et font preuve d’initiatives, de souhaits et de préférences. Elles sont cognitivement équivalentes à l’intellect humain.
A noter que l’IA générale reste largement théorique à ce stade.
Algorithmes et Prise de Décision
Au cœur de l’IA se trouvent des algorithmes, des ensembles de règles et d’instructions programmées pour effectuer des tâches spécifiques.
Ces algorithmes permettent aux machines d’analyser des données, d’apprendre de ces données et de prendre des décisions ou de faire des prédictions basées sur ces apprentissages. La prise de décision assistée par l’IA peut être vue dans des applications aussi variées que la recommandation de produits sur une plateforme de commerce électronique, la détection de fraudes dans les transactions financières et le diagnostic médical.
Ce que l’On Peut Lui Demander de Faire
Au cœur se trouvent des « familles » de modèles, chacune avec des fonctions et des applications spécifiques. Ces familles illustrent la variété des tâches que l’IA peut accomplir, allant de la prédiction de valeurs continues à la génération de contenu nouveau et inédit.
Ces familles de modèles d’IA démontrent la polyvalence et la capacité d’adaptation de l’intelligence artificielle. Elles soulignent également la manière dont l’IA peut être appliquée dans une multitude de contextes, transformant de nombreux secteurs par son potentiel à analyser, prédire, regrouper et étoffer (voir créer de toute pièce).
En comprenant ces bases, nous allons être mieux équipés pour explorer les implications plus larges de l’IA dans les paragraphes suivants.
Modèles de Régression
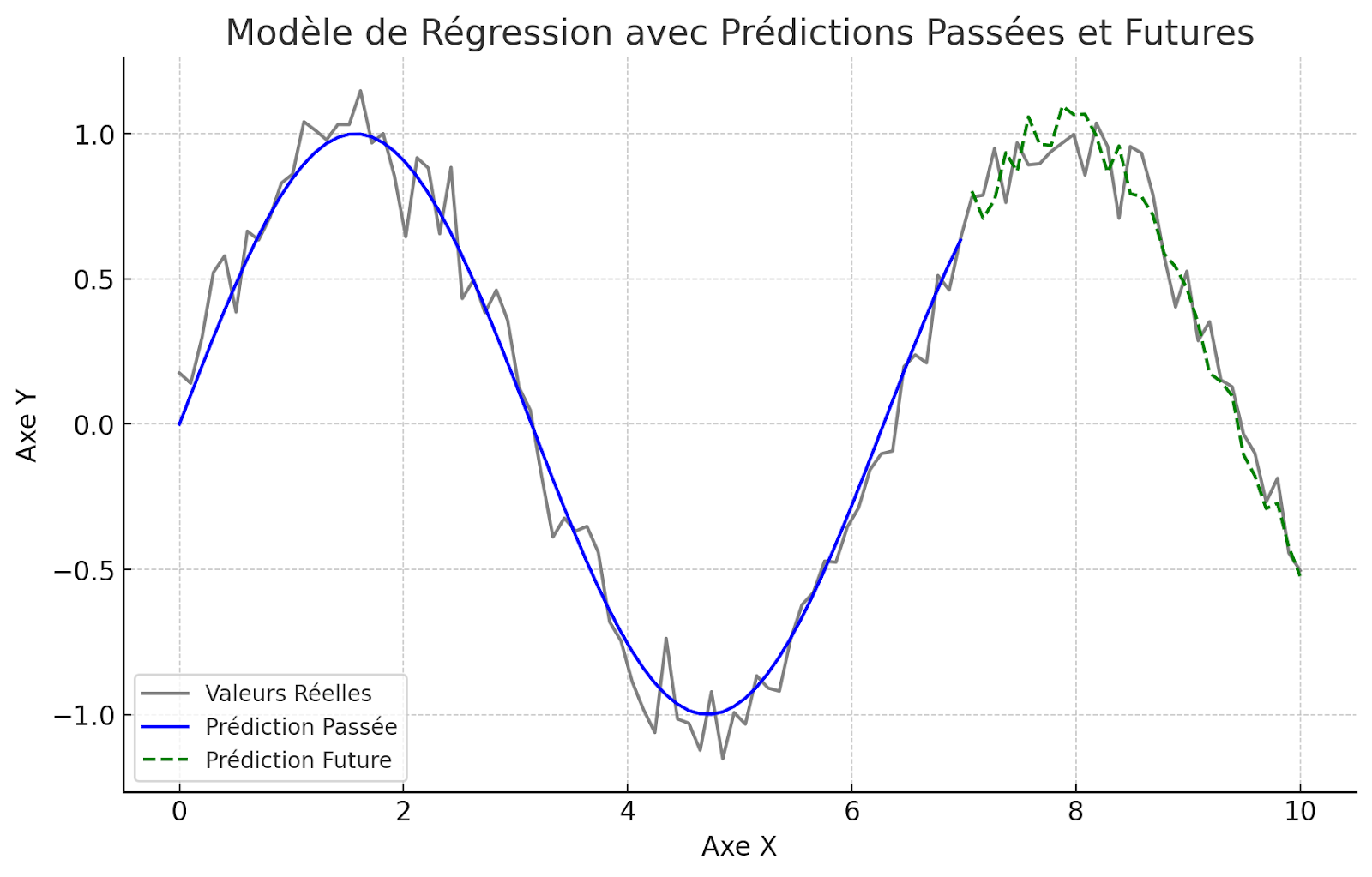
Ces modèles sont essentiels pour prédire des valeurs continues. Ils analysent les relations entre différentes variables pour estimer comment la variation d’une variable influence une autre.
Par exemple, un modèle de régression pourrait prédire le prix d’une maison en se basant sur des critères tels que sa taille, son emplacement et son âge ou l’ampleur des travaux accomplis, fournissant ainsi des estimations précieuses pour des secteurs comme l’immobilier ou la finance.
Modèles de Classification
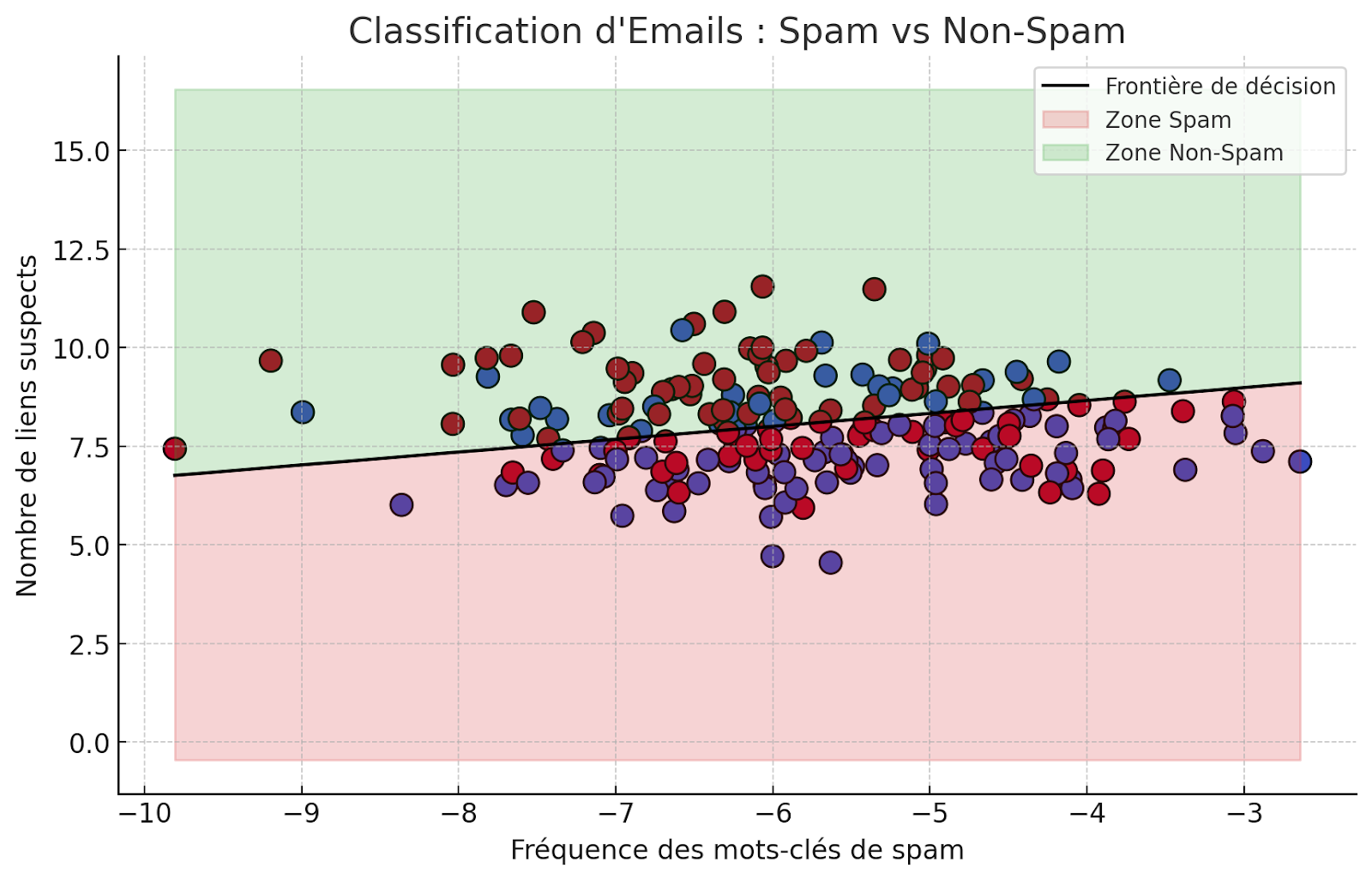
Les modèles de classification sont conçus pour identifier à quelle catégorie appartient une entrée donnée. Ils sont capables de traiter des informations et de décider de la catégorie la plus appropriée pour ces données.
Un usage courant comprend la détection de spams dans les boîtes de réception, où l’IA détermine si un émail est un spam ou un message légitime, améliorant ainsi la gestion des emails.
Modèles de Clustering
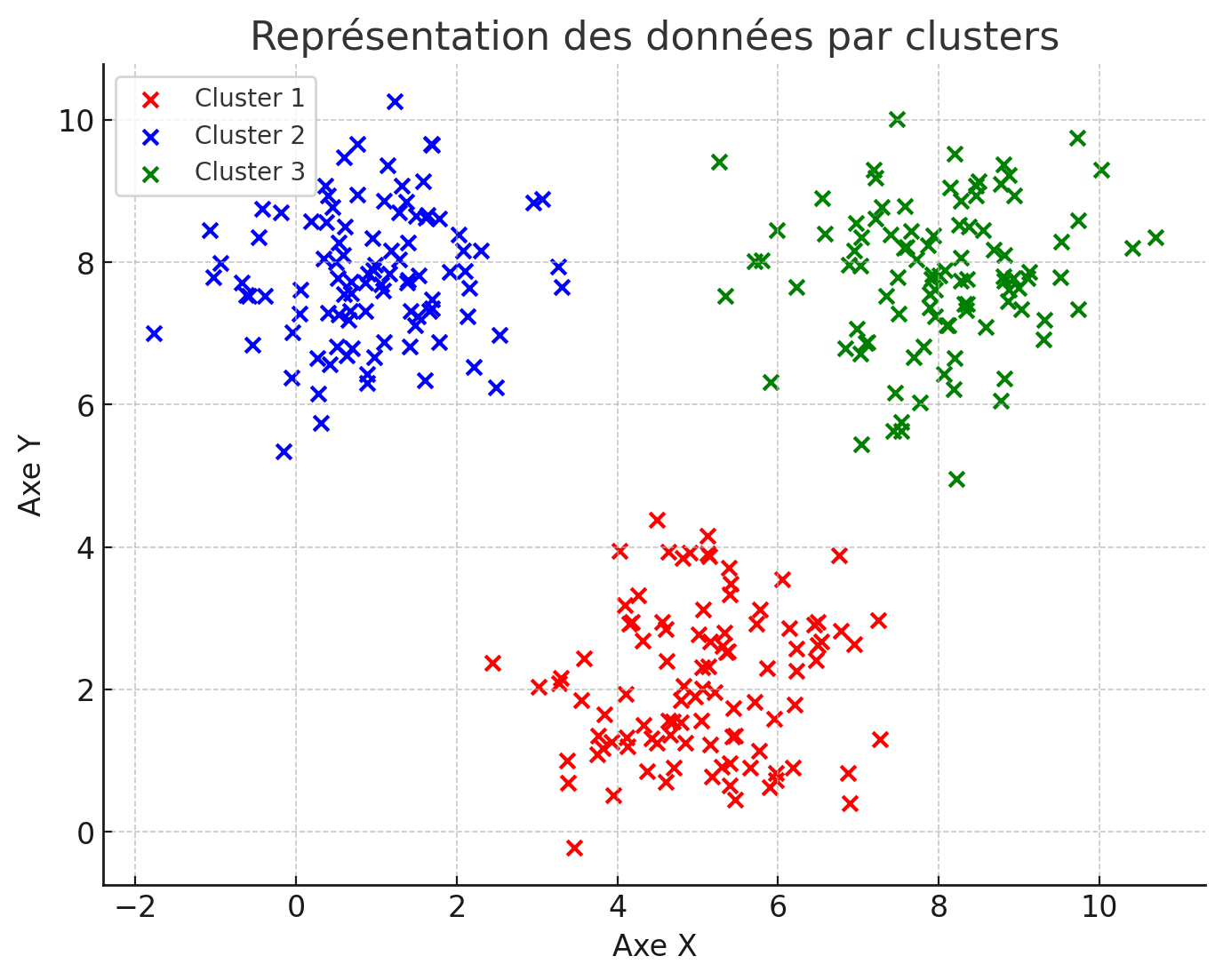 Le clustering, ou regroupement, consiste à organiser des éléments en groupes en fonction de leurs similarités. Ces modèles sont particulièrement utiles pour découvrir des structures cachées dans les données, comme regrouper des clients selon leurs habitudes de consommation. Ce processus peut par exemple aider les entreprises à cibler plus efficacement leurs stratégies de marketing grâce à une meilleure compréhension des préférences de leurs clients.
Le clustering, ou regroupement, consiste à organiser des éléments en groupes en fonction de leurs similarités. Ces modèles sont particulièrement utiles pour découvrir des structures cachées dans les données, comme regrouper des clients selon leurs habitudes de consommation. Ce processus peut par exemple aider les entreprises à cibler plus efficacement leurs stratégies de marketing grâce à une meilleure compréhension des préférences de leurs clients.
Modèles Génératifs
Les modèles génératifs ouvrent de nouvelles frontières en générant des données qui imitent la distribution des données d’entraînement.

Ils sont utilisés pour créer des images, du texte, de la musique et d’autres formes de contenu en se basant sur l’apprentissage de patterns dans de vastes ensembles de données. A cet égard, et je ne serais pas surpris, à terme, de voir se développer des systèmes permettant de simuler efficacement des odeurs et des sensations tactiles
Ces modèles sont à l’origine d’avancées créatives spectaculaires impossibles à concevoir en un temps de création si bref.
Les modèles génératifs représentent une avancée significative dans le domaine de l’IA, offrant la possibilité de créer du contenu nouveau et inédit. Parmi ces modèles, les Small/Large Language Models (S/L.L.M) et les modèles de diffusion se distinguent par leurs applications et leurs mécanismes uniques.
Malgré leur capacité à créer des contenus qui semblent cognitivement riches, les modèles génératifs, qu’ils traitent du texte, de l’audio, ou des images.. ne possèdent pas de véritable compréhension de ce qu’ils génèrent. Ils offrent l’illusion de la cognition, reposant sur des analyses statistiques des données fournies. Cette limitation souligne un aspect fondamental de l’IA actuelle : bien qu’elle puisse imiter l’intelligence humaine à certains égards, elle reste essentiellement un outil avancé d’analyse et de génération de patterns.
Avec les dernières itérations (comme SORA d’Open AI) qui génèrent des mondes virtuels en mouvement, ou GEMINI de Google qui s’est montré capable de simuler entièrement un jeu vidéo en partant d’instructions simples et en prenant en compte les commandes de l’utilisateur.. Il est difficile de rester sans réaction devant l’avancement époustouflant de ces simulateurs grande échelle.
Malgré tout, même si l’état de la base de connaissance est extrêmement vaste, nous sommes et restons dans la catégorie des IA ouvrière presque générale mais tout de même passives.
Les Language Models (LMs) : La parole et la Machine
Un Small/Large Language Model (S/L.L.M.) est une forme sophistiquée de modèles d’apprentissage automatique, entraînée sur de vastes corpus de texte. Grâce à cette formation, ils peuvent « comprendre » l’expression écrite et interagir en utilisant le langage naturel.
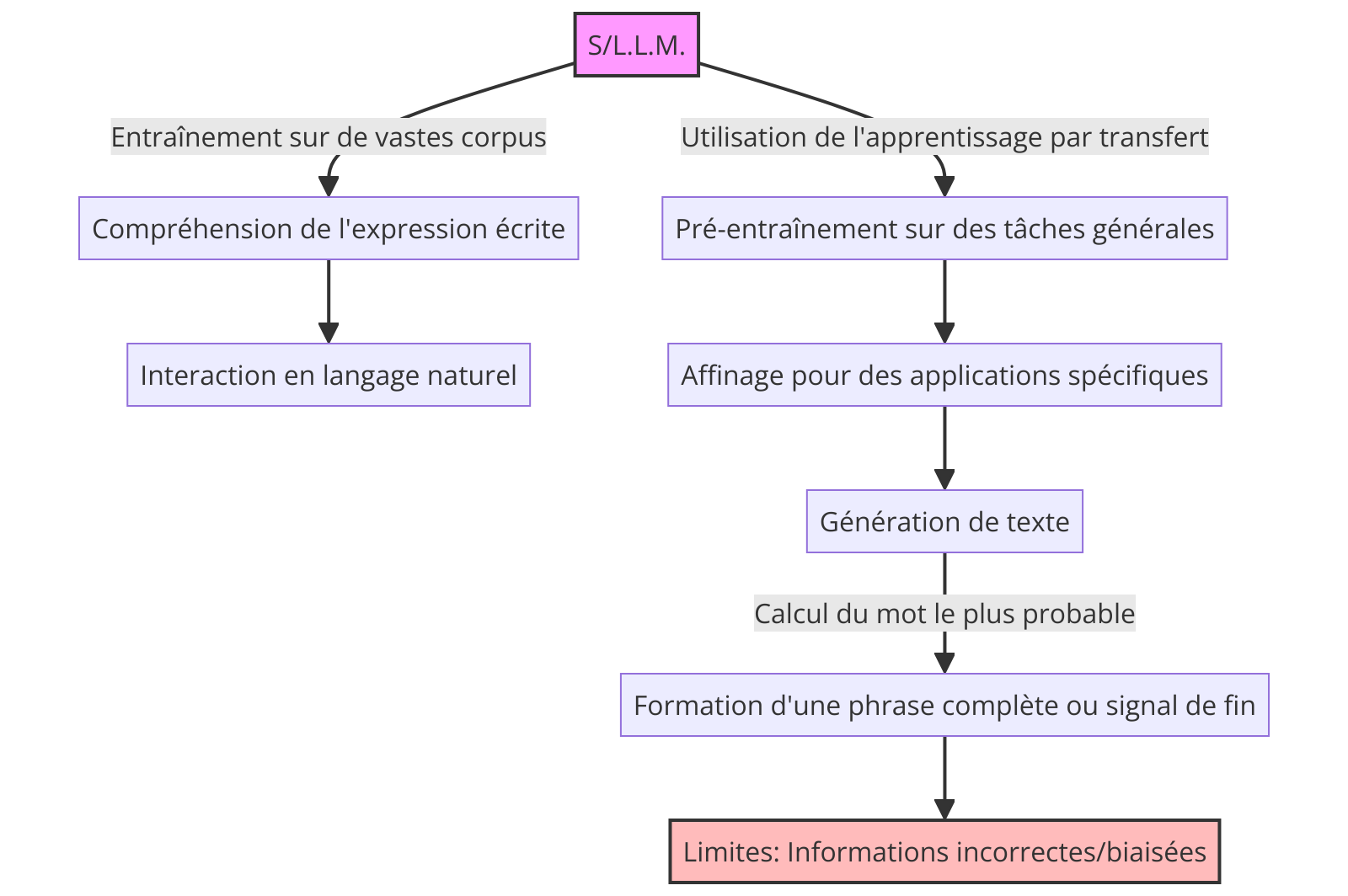 L’adjectif Small ou Large identifie le nombre d’hyper-paramètres du modèles (pour simplifier et par métaphore, nous dirons ici les neurones de ce cerveau électronique simulé) qui sont respectivement assez peu nombreux pour fonctionner sur des machine consumer (comme les ordinateurs que l’on achète en grande surface) ou alors qui nécessitent des datacenter pour pouvoir être exploités.
L’adjectif Small ou Large identifie le nombre d’hyper-paramètres du modèles (pour simplifier et par métaphore, nous dirons ici les neurones de ce cerveau électronique simulé) qui sont respectivement assez peu nombreux pour fonctionner sur des machine consumer (comme les ordinateurs que l’on achète en grande surface) ou alors qui nécessitent des datacenter pour pouvoir être exploités.
Les S/L.L.M utilisent l’apprentissage par transfert, une méthode où les modèles sont d’abord pré-entraînés sur des tâches générales (comme prédire le mot suivant dans une phrase), puis affinés pour des applications spécifiques, telles que la traduction, la génération de contenu ou l’exécution de commandes et suivre des instructions qui seront alors dictées en langage naturel (au lieu d’un programme informatique).
Ces modèles produisent du texte en calculant le mot le plus probable suivant, basé sur les mots précédents et continuent ce processus jusqu’à la formation d’une phrase complète ou jusqu’à rencontrer un signal de fin.
Bien qu’impressionnants, les S/L.L.M ont leurs limites. Ils génèrent du texte en s’appuyant sur des patterns appris, sans posséder une compréhension réelle du monde, ce qui peut mener à la production d’informations incorrectes ou biaisées, reflétant les préjugés présents dans les données d’entraînement.
Modèles de Diffusion : L’image et la Machine
Les modèles de diffusion génèrent des données analogiques, comme des images (ou une séquence d’images) ou des sons, en simulant un processus qui transforme du bruit aléatoire en une structure organisée, créant ainsi des résultats qui imitent les données d’entraînement.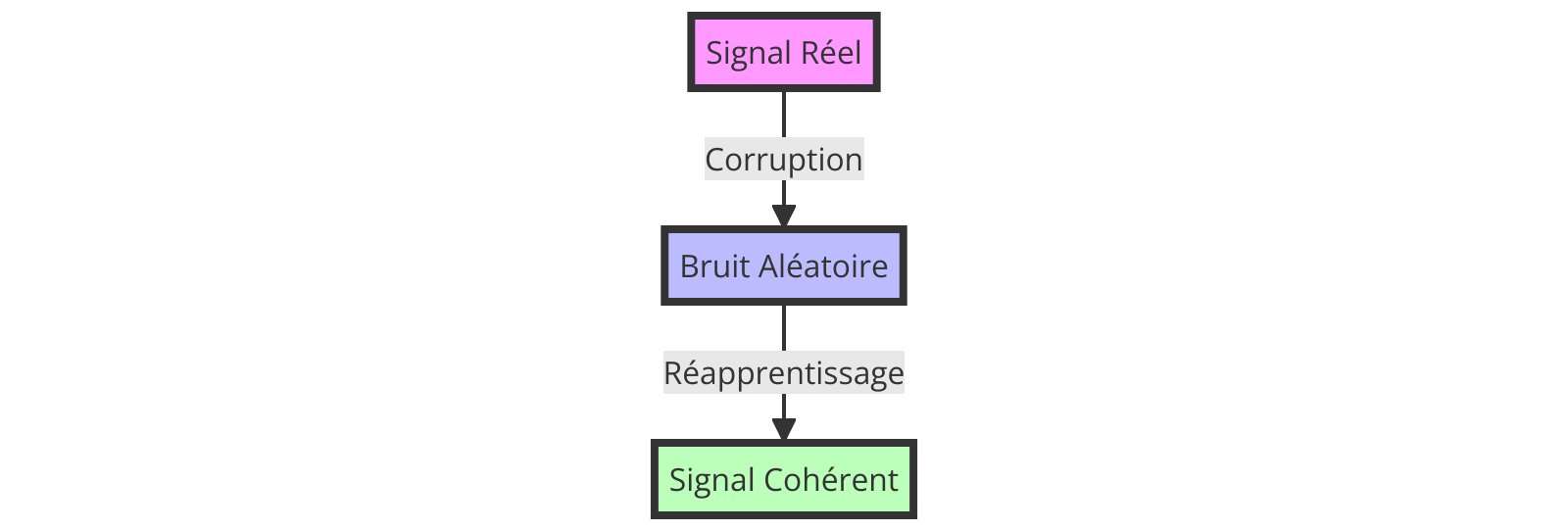
Ce processus se déroule en deux étapes : la corruption, où un signal réel est progressivement transformé en bruit et le processus inverse, où le modèle réapprend à transformer ce bruit en un signal cohérent.
Ce fonctionnement, bien que semblant contre-intuitif, est en fait similaire à la façon dont les humains procèdent avec les informations nouvelles d’ordre analogiques, c’est à dire en les décomposant en signaux connus avant d’apprendre à les distinguer: par exemple un nouveau parfum d’abord ça sent la camomille, puis on l’assimile au citron pour enfin apprendre qu’il s’agit de citronnelle.
Ces modèles peuvent parfois générer des éléments irréalistes et le processus de création peut être lent. Ils sont sujets aux « hallucinations », produisant des résultats qui, bien que visuellement ou auditivement convaincants, ne correspondent pas toujours à des représentations fidèles du réel.
Comparaison et Interactions
Bien que la BI, le ML et l’IA puissent sembler similaires à première vue, leurs objectifs et applications sont distincts. La BI est axée sur l’analyse de données historiques pour guider les décisions actuelles, tandis que le ML se concentre sur la prédiction de tendances futures à partir de données existantes.
L’IA, quant à elle, englobe une vision plus large, cherchant à simuler l’intelligence humaine dans sa capacité à résoudre des problèmes complexes.
Ensemble, ces technologies offrent un éventail complet d’outils pour transformer l’information en action.
Conclusion
Avec cette introduction, nous posons les fondations pour la compréhension des articles qui suivront cette rubrique.
J’espère avoir réussi à vous motiver pour en apprendre davantage au sujet de l’IA et vous avoir donné l’envie de suivre la suite de nos publications dont le but est de démystifier les avancées dans ce secteur concurrentiel et à fort impact sociétal.
Au moment de la rédaction de cet article, l’auteur Martino BETTUCCI occupait la fonction suivante : formateur et entrepreneur IA et Blockchain, notamment en tant que (co)fondateur de P2Enjoy. Retrouvez-le sur Linkedin et Twitter.
Maximisez votre expérience Cointribune avec notre programme 'Read to Earn' ! Pour chaque article que vous lisez, gagnez des points et accédez à des récompenses exclusives. Inscrivez-vous dès maintenant et commencez à cumuler des avantages.

Cointribune, c'est tout d'abord une communauté, un espace d'expression, où chacun est en mesure de partager ses connaissances et son savoir dans le domaine du Bitcoin, de la crypto ou de la blockchain. Merci à tous nos contributeurs qui nous aident tous les jours à vulgariser ce nouvel univers.
Les contenus et produits mentionnés sur cette page ne sont en aucun cas approuvés par Cointribune et ne doivent pas être interprétés comme relevant de sa responsabilité.
Cointribune s’efforce de communiquer aux lecteurs toutes informations utiles à disposition, mais ne saurait en garantir l’exactitude et l’exhaustivité. Nous invitons les lecteurs à se renseigner avant toute action relative à l’entreprise, ainsi qu’à assumer l’entière responsabilité de leurs décisions. Cet article ne saurait être considéré comme un conseil en investissement, une offre ou une invitation à l’achat de tous produits ou services.
L’investissement dans des actifs financiers numériques comporte des risques.
Lire plus